|
I am a Software Engineer at Latitude AI, building computer vision models for self-driving vehicles. Previously, I was a Machine Learning Research Engineer at Neural Magic, which recently got acquired by RedHat. Before this, I worked at Argo AI as a Research Engineer. Before that, I was a Masters student at the Robotics Institute, Carnegie Mellon University, where I worked with Prof. Deva Ramanan. Before that, I worked at Video Analytics Lab, Indian Institute of Science, on computer vision problems and at Microsoft, improving search at Bing scale. I graduated from Indian Institute of Technology Kharagpur majoring in Mathematics and Computing. I have enjoyed working on a diverse set of topic - ranging from video summarisation, motion planning for mobile robots to applying machine learning for pressing issues such as estimating insulin intake, detecting tumorous cells, etc. Email / CV / Google Scholar / LinkedIn / Github |

|
|
I am excited about developing state-of-the-art algorithms and formulating relevant research problems that enablerobots to sense and perceive the world as humans do. Presently, my research is focused on autonomous driving andpoint clouds, unsupervised learning, domain adaptation and transfer learning Reviewer: CVPR 2022-2024, ICRA 2021, 2023-2024, NeurIPS 2023 DGM4H, NeurIPS 2021 ICBINB, MLRC 2020, 2022. |
|
|
|
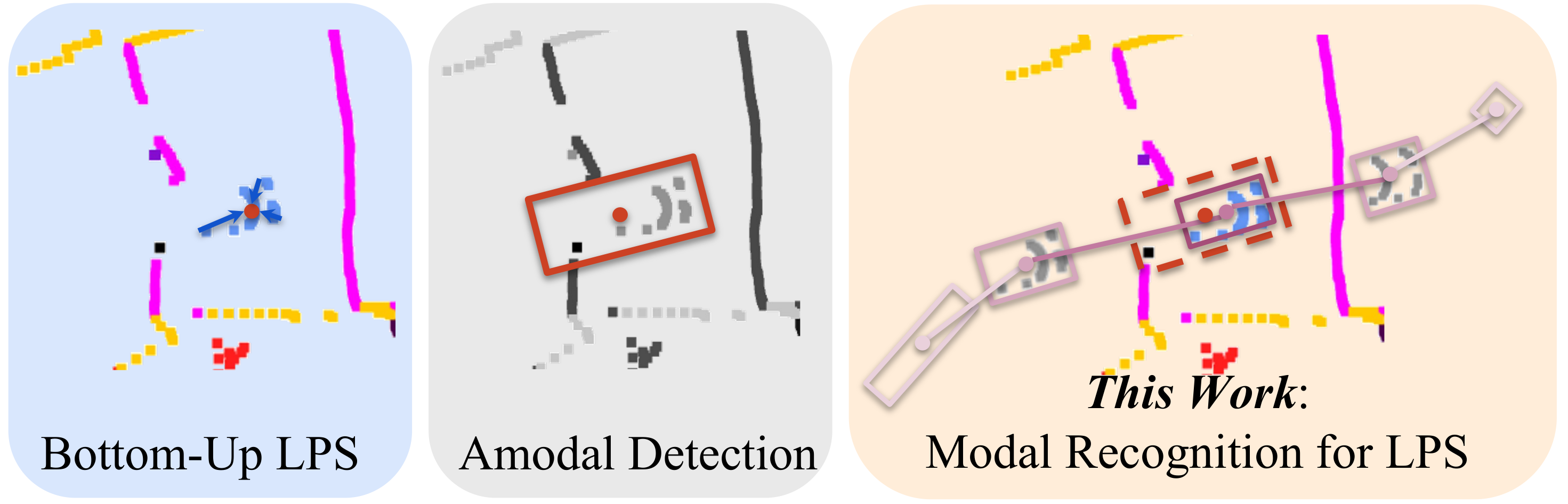
Abhinav Agarwalla*, Xuhua Huang*, Jason Ziglar, Francesco Ferroni, Laura Leal-Taixé, James Hays, Aljoša Ošep, Deva Ramanan IROS, 2023 paper / code The paper introduces a detection-centric network for lidar panoptic segmentation (LPS) and tracking on 3D Lidar point clouds, challenging the conventional "bottom-up" approach. The network utilizes trajectory-level point supervision to obtain `modal` annotations. These are then utilized to predict fine-grained instance segments across time. |

|
Abhinav Agarwalla*, Deepak Babu Sam*, Jimmy Joseph, Vishwanath A. Sindagi, R. Venkatesh Babu, Vishal M. Patel ECCV, 2022 paper / code Existing self-supervised approaches can learn good representations, but require some labeled data to map these features to the end task of crowd density estimation. We mitigate this issue with the proposed paradigm of complete self-supervision, which does not need even a single labeled image. |
|
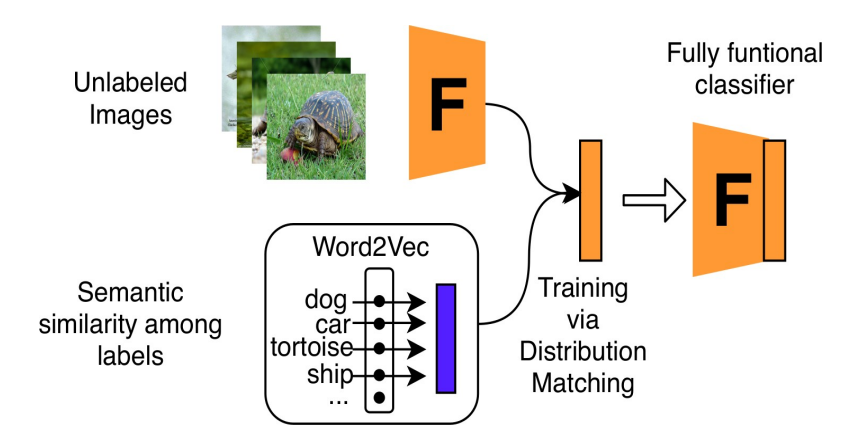
Abhinav Agarwalla*, Deepak Babu Sam*, R. Venkatesh Babu AAAI, 2022 ICML 2021 Workshop on Self-Supervised Learning for Reasoning and Perception poster Existing unsupervised methods require some annotated samples to facilitate the final task-specific predictions. Instead, we leverage the distribution of labels for supervisory signal such that no image-label pair is needed for training a classifier. |
|
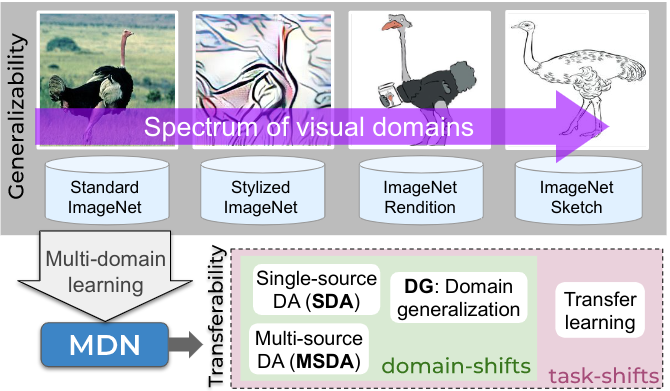
Abhinav Agarwalla*, Jogendra Nath Kundu*, Suvaansh Bhambri, Varun Jampani, R. Venkatesh Babu Technical Report paper We propose a universal framework to handle both task and domain shifts, and report state-of-the-art results on single/multi-source domain adaptation and domain generalisation. |
|
Abhinav Agarwalla*, Arnav Kumar Jain*, KV Manohar, Arpit Tarang Saxena, Jayanta Mukhopadhyay CoDS - COMAD 2018 paper We integrate learning and motion planning for soccer playing differential drive robots using Bayesian optimisation. |

|
Avisek Lahiri*, Abhinav Agarwalla*, Prabir Kumar Biswas ICVGIP 2018 paper / code |
|
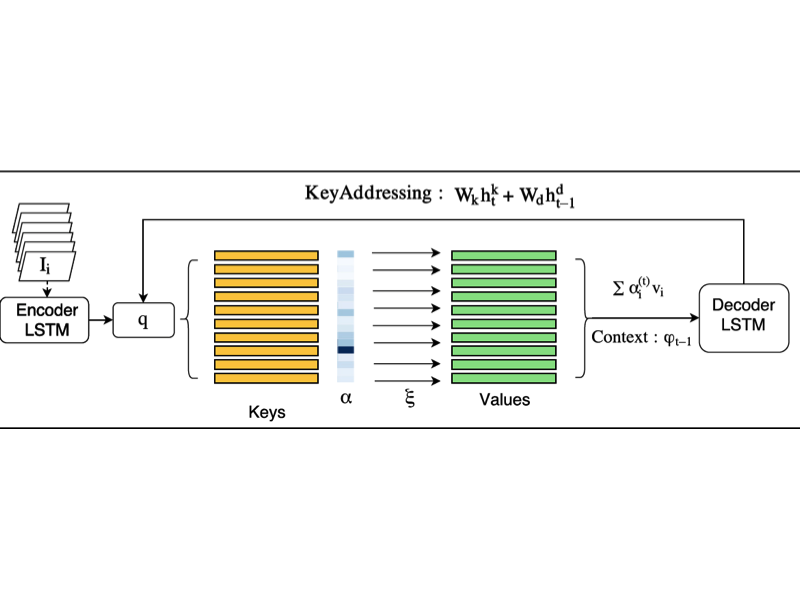
Arnav Kumar Jain*, Abhinav Agarwalla*, Kumar Krishna Agrawal, Pabitra Mitra DeepVision , CVPR 2017 paper In this paper, we introduce Key-Value Memory Networks to a multimodal setting and a novel key-addressing mechanism to deal with sequence-to-sequence models. The proposed model naturally decomposes the problem of video captioning into vision and language segments, dealing with them as key-value pairs. |
|
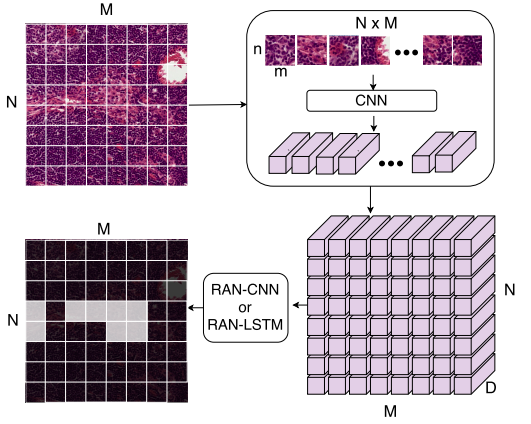
Abhinav Agarwalla*, Muhammad Shaban, Nasir M Rajpoot Deep Learning in Irregular Domains, BMVC 2017 paper / code CNNs have become the preferred choice for most computer vision tasks. However, these are not best suited for multi-gigapixel resolution Whole Slide Images (WSIs) of histology slides due to large size of these images. This work address this issue with novel 2D-LSTM + CNN network for tumor segmentation. |
|
|